
W poprzedniej odsłonie tego cyklu zaczęliśmy powoli wkraczać w temat algorytmów, które mogą pojawiać się podczas rozmów kwalifikacyjnych na stanowisko inżyniera oprogramowania. Jako że udało nam się dopiero lekko zarysować powierzchnię tego bardzo szerokiego tematu, w dzisiejszym artykule dalej będziemy drążyć ten temat. Dodatkowo, jeżeli macie jakieś tematy, które chcielibyście abyśmy poruszyli w tym cyklu, piszcie śmiało na marek.makuch@it-leaders.pl. Postaram się odpowiedzieć w mailu, bądź zawrzeć odpowiedź w kolejnych artykułach. Na sam koniec, przypominam tylko że o ile sam temat algorytmów i struktur jest agnostyczny językowo, to w tym artykule będziemy prezentować rozwiązania w języku Java. Po tym krótkim wstępie, możemy zaczynać 😊
>> Sprawdź nasze aktualne oferty w obszarze: Java Developer
Czym jest rekurencja? Podaj przykłady gdzie jest wykorzystywana?
Definicja rekurencji jest stosunkowo prosta – otóż rekurencja oznacza odwoływanie się danej funkcji do siebie samej. Przykładem „z życia wziętym” mogą być dwa lustra, ustawione po przeciwnych stronach stołu. W każdym luster będzie się odbijać odbicie lustra po drugiej stronie, tworząc wrażenie nieskończonego ciągu odbić zawartych w każdym z luster.
Przykładem problemu, jaki możemy rozwiązać przy pomocy funkcji rekurencyjnej jest chociażby znalezienie n-tego elementu ciągu Fibonacciego, przedstawione na wycinku kodu poniżej:
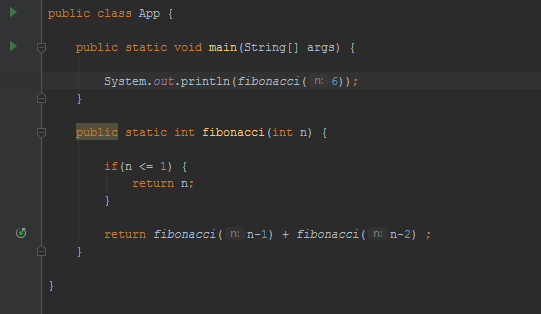
To wiemy z definicji ciągu Fibonacciego, że element zerowy jest równy zero, element drugi jest równy jeden, natomiast każdy następny jest równy sumie dwóch poprzednich. Jak widzimy w powyższym rozwiązaniu, funkcja fibonacci(int n) w swoim ciele odwołuje się do samej siebie, pomniejszając przy tym zadany argument kolejno o 1 oraz 2, jako że każdy n-ty numer jest sumą dwóch poprzednich, reprezentowanych przez fibonacci(n-1) oraz fibonacci(n-2).
Pierwszym przykładem wykorzystywania rekurencji może być chociażby powyższy przykład wyliczania n-tego elementu ciągu Fibonacciego. Kolejnym przykładem może być wykorzystanie rekurencji w sortowaniu przez scalanie (merge sort) – gdzie, w dużym skrócie, dzielimy ciąg wartości na coraz mniejsze elementy, w celu posortowania tego ciągu (więcej na ten temat dalej w artykule). Jeszcze jednym przykładem wykorzystania rekurencji może być jej wykorzystanie w przeszukiwaniu w głąb grafów (Depth First Search), który jest wykorzystywany w wyznaczaniu drogi.
Największą zaletą funkcji rekurencyjnej jest to iż wyraża ona w prosty sposób intencje autora. Bardzo często rozwiązania rekurencyjne czyta i pisze się dużo łatwiej niż rozwiązania iteracyjne. Tego typu funkcje mają jednak jedną, bardzo poważną wadę – bardzo szybko potrafią pochłonąć duże ilości pamięci, narażając nas na niezbyt przyjemny błąd przepełnienia stosu.
Czym są i jak działają algorytmy typu Divide&Conquer)? Gdzie są wykorzystywane takie algorytmy?
Algorytmy z dziedziny Divide&Conquer są budowane według specjalnego sposobu rozwiązywania problemu. Po pierwsze, w takim algorytmie musimy podzielić nasz główny problem na jak najmniejsze kawałki, tak, aby rozwiązać każdy z tych kawałków osobno. Po rozwiązaniu każdego z tych osobnych problemów, staramy się połączyć je w taki sposób, aby stworzyły one jedno zintegrowane i kompleksowe rozwiązanie.
Rozwiązania takie mogą być wykonywane dzięki rekurencji, gdzie dzielimy elementy na coraz mniejsze części, do momentu aż każda z tych części jest na tyle mała, że rozwiązanie problemu z nią związanego staje się dużo prostsze.
Przykładami problemów, przy których wykorzystywana jest chociażby sortowanie (sortowanie przez scalanie, szybkie sortowanie), wyszukiwanie binarne czy algorytm Strassena, wykorzystywany do mnożenia macierzy.
Jak wygląda algorytm wyszukiwania binarnego?
Wyszukiwanie binarne jest bardzo częstym tematem, pojawiającym się na rozmowach, dotyczących algorytmów. Jest to jeden z łatwiejszych algorytmów, który umożliwia szybkie znalezienie szukanego elementu nawet dla dużej ilości posortowanych danych wejściowych. Pod spodem przedstawiamy kroki, które musimy wykonać (zakładając, że mamy zbiór liczb posortowanych od najmniejszej do największej):
- Zaczynamy biorąc środkowy element zbioru, jeżeli ten element jest elementem szukanym, zwracamy indeks tego elementu. Jeżeli nie trafiliśmy w szukaną wartość to
- Jeżeli szukana wartość jest większa niż pobrana wartość, a pozostały ciąg liczb ma więcej niż dwa elementy, to do przeszukiwania pobieramy wartości z prawej strony środkowego elementu i wracamy do pierwszego kroku.
- Jeżeli szukana wartość jest mniejsza niż pobrana wartość, a pozostały ciąg liczb ma więcej niż dwa elementy, to do przeszukiwania pobieramy wartości z lewej strony środkowego elementu i wracamy do pierwszego kroku.
- Jeżeli w ciągu pozostała nam jedna wartość i nie jest ona równa poszukiwanemu elementowi zwracamy błąd – w szeregu nie ma szukanej wartości.
Przy wyszukiwaniu binarnym musimy pamiętać iż szereg musi być posortowany, inaczej nie możemy wykorzystać powyższego algorytmu.
Jak wygląda przykładowa implementacja algorytmu wyszukiwania binarnego?
To pytanie często pojawia się na rozmowach kwalifikacyjnych, gdyż sam algorytm jest dosyć prosty i szybki do napisania. Poniżej zamieszczamy naszą implementację:
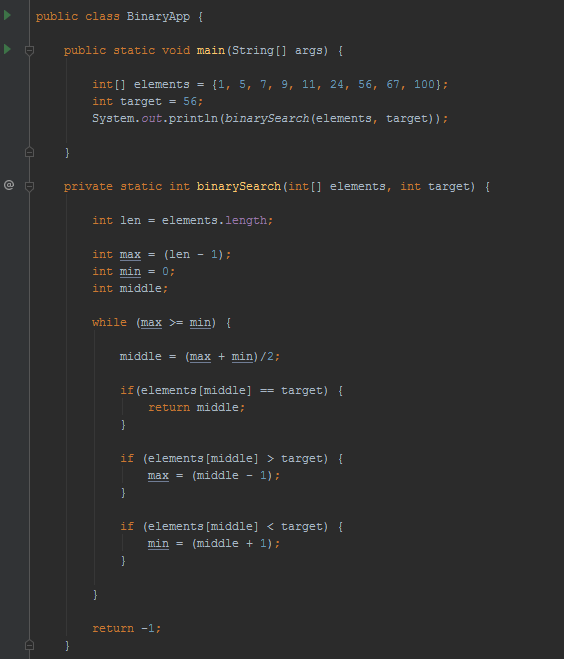
Jak widać na powyższym obrazku, w metodzie binarySearch() definiujemy cztery zmienne, które przechowują długość naszego ciągu, maksymalny element (max) oraz minimalny element (min), w których przechowywane będą informacje o indeksach granicznych naszego pomniejszającego się ciągu. Następnie w pętli wykonujemy wszystkie opisane powyżej kroki aby znaleźć szukany przez nas element. W przypadku braku tego elementu zwracamy wartość -1. Uśredniona wartość wydajności czasowej dla tego algorytmu wynosi O(logn).
Czym jest sortowanie przez scalanie (merge sort)? Jaka jest wydajność czasowa tego algorytmu?
Sortowanie przez scalanie jest algorytmem z rodziny Divide&Conquer. Kategoria ta oznacza, iż aby rozwiązać dany problem (w naszym przypadku będzie to sortowanie) musimy rekurencyjnie podzielić nasz argument wejściowy na coraz mniejsze części, aż do momentu, gdy zostaniemy z przypadkiem bazowym (elementów którego nie możemy już bardziej rozdzielić). Aby wykonać sortowanie przez scalanie musimy wykonać następujące czynności:
- Jeżeli ciąg ma jeden element, zwróć go.
- Znajdź środkowy element twojego ciągu tak, aby podzielić go na dwie części (nie są to połowy, gdyż części nie muszą być równe, mogą się różnić w długości o 1).
- Wywołaj funkcję sortowania przez scalanie dla lewej części ciągu.
- Wywołaj funkcję sortowania przez scalanie dla prawej części ciągu.
- Posortuj zwrócone wartości z dwóch poprzednich kroków.
Jak widać algorytm rekursywnie odwołuje się do siebie samego w kroku 2 oraz 3. Samo zrozumienie tego algorytmu jest dużo prostsze jeżeli przyjrzymy się jak wygląda on na rysunku:
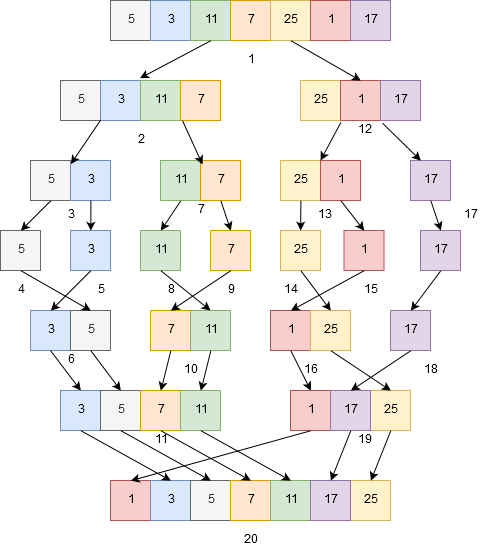
Przejdźmy sobie po kilku krokach powyższego rysunku w celu lepszego zrozumienia. Krok pierwszy dzieli nasz szereg na dwie części, lewą i prawą. Jako że w naszym opisie wykonywania algorytmu najpierw odnosimy się do lewej części wyniku tego działania to następnie wykonują się operacje 2 (w której dzielimy lewy wynik operacji 1) i 3 (w którym dzielimy lewy wynik operacji 2). W kroku nr 4 trafiamy już na obiekt, którego nie możemy dalej podzielić, dlatego przechodzimy do operacji 5, czyli próby podzielenia prawej części wyniku operacji 3. Jako że wynik 4 i 5 operacji jest już najmniejszym możliwym elementem, dokonujemy operacji scalenia obydwu wyników w operacji 6. Jako że nie mamy z czym scalić wyniku operacji 6, wracamy do prawego wyniku operacji 2, aby podzielić go na możliwie jak najmniejsze elementy.
Powołując się na logikę, którą wykorzystywaliśmy poprzednio, wykonujemy operacje 8 (lewe dzielenie, sprawdzenie), 9 (prawe dzielenie, sprawdzenie) i 10 (scalenie 8 i 9). Jako że mamy już lewy i prawy wynik operacji 2, możemy scalić je, iterując po poszczególnych elementach posortowanej lewej i prawej części, wstawiając elementy na odpowiednie miejsca. Tą samą operację wykonujemy dla prawego wyniku operacji 1 i, przechodząc przez kroki 12 – 19, sortując go. Następnie, mając lewy i prawy posortowany wynik operacji 1, możemy dokonać scalenia ich w posortowaną całość. Ufff 😉
Już dzięki samej obserwacji powyższego obrazka możemy zauważyć że metoda sortowania z pewnością jest szybsza niż sortowanie przez wstawianie. Złożoność czasowa tego algorytmu wynosi O(nLogn) dla każdego przypadku, najszybszego, najwolniejszego oraz średniego. Dzieje się tak dlatego iż algorytm zawsze dzieli wejściowy szereg na dwie części.
Poprzednie artykuły z cyklu:
Rozmowa kwalifikacyjna z Javy? Żaden problem! – cz. I (String)
Rozmowa kwalifikacyjna z Javy? Żaden problem! – cz. II (Kolekcje)
Rozmowa kwalifikacyjna z Javy? Żaden problem! Cz. III (Core)
Rozmowa kwalifikacyjna z Javy? Żaden problem! Cz. IV (Multithreading)
Rozmowa kwalifikacyjna z Javy? Żaden problem! Cz. V (Wzorce projektowe)
Rozmowa kwalifikacyjna z Javy? Żaden problem! Cz. VI (Spring)
Rozmowa kwalifikacyjna z Javy? Żaden problem! Cz. VII (Spring)
Rozmowa kwalifikacyjna z Javy? Żaden problem! Cz. VIII (JPA)
Autor: Marek Makuch
Oryginalny wpis pojawił się na naszym blogu w listopadzie 2018r.
IT-Leaders.pl to pierwsza w Polsce platforma łącząca Specjalistów IT bezpośrednio z pracodawcami. Anonimowy, techniczny profil i konkretnie określone oczekiwania finansowe to tylko niektóre z cech wyróżniających platformę. Zarejestruj się i zobacz jak Cię widzi pracodawca.