
Przygotowaliśmy dziś dla Was kolejny artykuł traktujący o pytaniach i zagadnieniach pojawiających się podczas rozmów kwalifikacyjnych w Javie. Temat będzie nieprzypadkowy, wynikający z tego, że ostatnio podczas pogawędki ze znajomym opowiedział mi on o swojej rozmowie rekrutacyjnej w pewnej firmie. Oprócz badania znajomości czystej Javy, pojawiło się również zagadnienie dotyczące Java Persistence API (w skrócie JPA), które jako bardzo ważne zagadnienie w dziedzinie programowania aplikacji Enterprise, natchnęło mnie do tego artykułu. Dlatego dzisiejszy artykuł będzie poświęcony właśnie JPA, z ewentualnymi wstawkami z jego implementacji (Hibernate, EclipseLink). Zapraszamy do lektury!
>> Sprawdź nasze aktualne oferty w obszarze: Java Developer
Czym jest Java Persistence API (JPA)?
JPA jest swojego rodzaju specyfikacją zawierająca standardy mapowania obiektowo-relacyjnego (ORM – object relational mapping), która obejmuje współpracę z bazami danych. JPA samo w sobie nie jest w stanie wykonywać operacji na bazach danych (czyli np. pobierania danych z bazy, zarządzania nimi, czy tworzenia rekordów w bazie). JPA należy rozumieć jako zbiór interfejsów, które muszą być zaimplementowane, aby przeprowadzać operacje na bazach danych z poziomu kodu Javy. Standard ten pozwala również na łatwe mapowanie obiektów Javowych do relacyjnych baz danych przy wykorzystaniu adnotacji lub plików konfiguracyjnych xml.
Jak zaimplementować JPA?
Z poprzedniej odpowiedzi wiemy, iż JPA samo w sobie nie jest w stanie przeprowadzać operacji na bazach danych. Dlatego są nam potrzebne implementacje tego standardu, które będą odpowiadały za operacje pobierania, aktualizowania, usuwania oraz dostarczania danych do naszej bazy. Powszechnymi przykładami implementacji tego standardu są:
- Hibernate: Najbardziej zaawansowany i najczęściej wykorzystywany, z obszerną dokumentacją i sporą społecznością;
- EclipseLink: Stworzony na podstawie innej implementacji – Toplink – jednak zdecydowanie bardziej zaawansowany. Często wykorzystywany z dobrą dokumentacją;
- DataNucleus: Dobrze udokumentowany, również dostawca JDO (więcej ciężko mi powiedzieć, niestety nie miałem większej styczności).
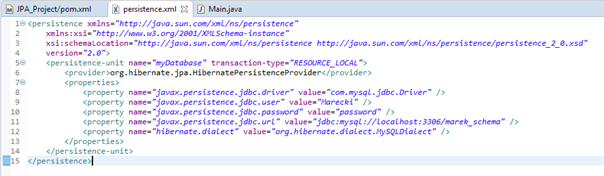
Co zawiera plik persistence.xml?
Ten plik zawiera informacje dotyczące Twojej bazy danych, przykładowo adres podłączenia się do Twojej bazy, nazwę użytkownika oraz hasło. Dodatkowo są w nim przechowywane informacje na temat encji znajdujących się w Twoim projekcie. Plik ten powinien być przechowywany w folderze META-INF w projekcie.
Persistence context zajmuje się zestawem encji (entities), przechowujących dane, które mogą zostać zapisane w naszej bazie danych. Głównym zadaniem context jest upewnienie się, że w danym EntityManagerze występuje dokładnie jeden obiekt danej encji.
Klasa, która ma być obiektem odpowiadającym rekordowi tabeli w naszej relacyjnej bazie danych, musi posiadać adnotację @Entity. Jest to informacja dla naszego dostawcy JPA iż dana klasa będzie zachowywana w bazie danych, a wszystkie akcje mające na celu zwrócenie nam informacji z danej tabeli, będą zwracać nam obiekty odpowiadające jednemu rzędowi z tej tabeli. Przykład można zobaczyć poniżej:

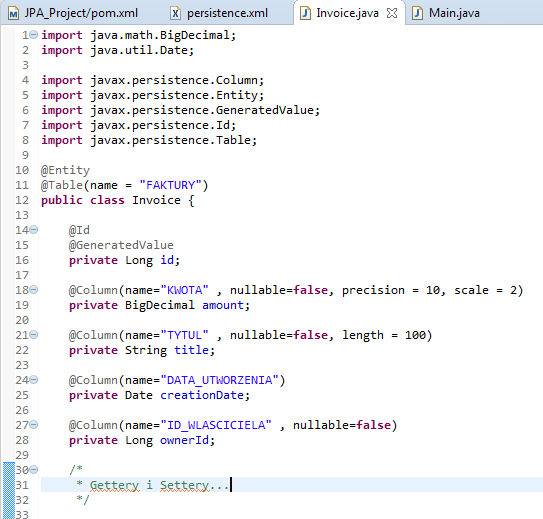
Jak widać, pola z naszej klasy odpowiadają poszczególnym kolumnom z tabeli. Wszystkie pola, które mają być pobierane i zapisywane do bazy, powinny również posiadać standardowe metody dostępowe (gettery i settery). Warto również zauważyć, iż to czy dane pole ma być zapisywane do bazy danych zależy tylko i wyłącznie od nas. Dzięki konkretnym adnotacjom możemy manipulować tym, co ma zostać zapisane do naszej bazy danych.
Czym jest EntityManager?
Manager Encji (EntityManager) jest naszym bezpośrednim łącznikiem pomiędzy poziomem aplikacji a poziomem relacyjnej bazy danych. Dzięki niemu jesteśmy w stanie wykonywać operacje na obiektach takie jak wyszukanie konkretnego obiektu, zapisanie obiektu do bazy danych, update tego obiektu oraz usunięcie go z naszego nośnika. W JPA wyróżniamy trzy typy EntityManagera:
- EntityManager zarządzany przez kontener i o zakresie transakcyjnym (Container Managed and Transaction Scoped Entity Manager);
- EM zarządzany przez kontener i o rozszerzonym zakresie (Container Managed and Extended Scope Entity Manager);
- EM zarządzany przez aplikację (Application Managed Entity Manager).
Teraz spróbujemy w krótki i w miarę łatwy sposób wyjaśnić działanie każdego z nich. Po pierwsze, co oznacza że EM jest zarządzany przez kontener, a nie przez aplikację? Wytłumaczeniem tego zagadnienia może być sytuacja, w której tym, co dzieje się w naszym EM, zarządzamy nie my (aplikacja), tylko jakiś kontener, dostarczony z zewnątrz, np. przez Springa. Przykładem mogą być tutaj transakcje, gdzie w Springu wystarczy, że oznaczymy jakąś operację adnotacją @Transactional, by nie musieć się martwić o otworzenie transakcji, wykonanie (commit) oraz w przypadku pojawienia się błędu, powrócenie do stanu poprzedniego (rollback). Jeżeli tą samą transakcją miałaby zarządzać aplikacja (my), to musielibyśmy wywołać odpowiednie metody EntityManagera, np. by otworzyć transakcję musielibyśmy wykorzystać entityManager.getTransaction.begin() (pobranie transakcji z EM a następnie jej otwarcie), natomiast aby ją wykonać musielibyśmy wywołać entityManager.getTransaction.commit().
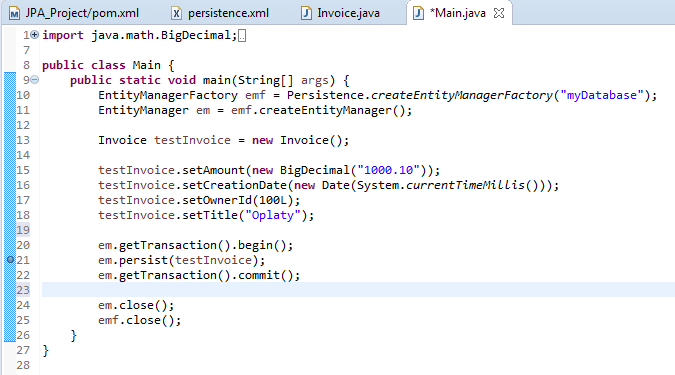
Różnica pomiędzy EM, zarządzanym przez kontener i o zakresie transakcyjnym a EM o zakresie rozszerzonym
W przypadku, kiedy wywoływana jest metoda w beanie o transakcyjnych zakresie, transakcja zostanie automatycznie rozpoczęta przez kontener i zostanie utworzony nowy persistence context (do którego dostęp mamy właśnie przez Entity Menagera). Kiedy wykonywanie metody dobiegnie końca, transakcja oraz kontekst zostaną zamknięte za Ciebie. Dużym plusem takiego rozwiązania jest to, że czyni ono nasz EM bezpieczny do pracy z wieloma wątkami.
W przypadku rozszerzonego zakresu, czas trwania naszego persistence context jest powiązany do czasu trwania naszego beana. EM może w tym momencie wykonywać dużo różnych transakcji, co można rozumieć, jako to, że EM jest dzielony przez wszystkie metody.
Jaka jest różnica pomiędzy trwałymi polami (persistent Fields) a trwałymi właściwościami (persistent Properties)?
Różnica polega tutaj na tym, w jaki sposób odbywa się dostęp do danych zawartych w encji. Jeżeli używamy trwałych pól to dostęp do danych odbywa się tutaj bezpośrednio poprzez pola, znajdujące się w danej encji. Wszystkie pola, które nie są oznaczone adnotacją @Transient (nie mylić ze słówkiem kluczowym transient z Javy), zostaną zapisane. W drugim przypadku pola naszej encji musza posiadać standardowe metody dostępowe (gettery i setery, w przypadku zmiennych typu Boolean może to być również is(Boolean), a adnotacje są zakładane na gettery danego pola.
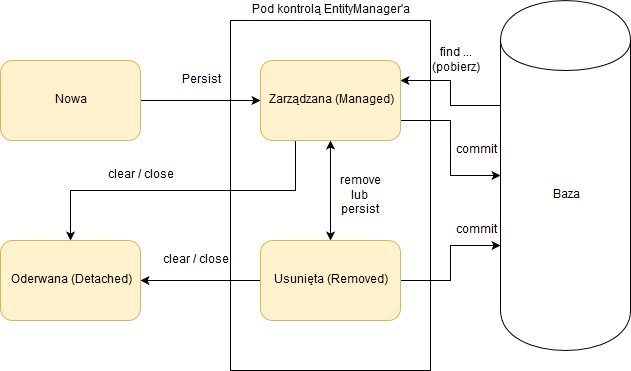
Jaki jest cykl życia encji w JPA?
Najważniejsze „momenty” w życiu encji w JPA to kolejno stany, w którym encja jest:
- New/transient (nowa/przejściowa) – w naszej aplikacji został utworzony obiekt danej encji, aczkolwiek nie został on jeszcze „podłączony” pod żaden obiekt typu EntityManager. W tej sytuacji obiekt istnieje tylko u nas w aplikacji, i w przypadku wykonania danej transakcji nie zostanie zapisany do niej.
- Managed/persisted (zarządzany/trwały) – obiekt został podłączony do EM przy pomocy metody persist. Obiekt jest w tym momencie zarządzany przez EM, i w przypadku, gdy zostanie wywołane wykonanie konkretnej transakcji, zostanie zachowany w bazie danych. Dodatkowo, jeżeli zostaną wykonane zmiany na danym obiekcie encji (przed wykonaniem transakcji), to zostaną one wykonane na obiekcie, który potem zostanie zapisany do bazy danych.
- Detached (oderwane) – jest to specjalny stan encji, w którym nie jest ona zarządzana już przez EntityMenager’a, lecz wciąż reprezentuje obiekt w bazie danych. Są one zazwyczaj zwracane do warstwy, w której mogą zostać pokazane do użytkownika końcowego. Zmiany na obiekcie w tym stanie mogą być wykonywane, aczkolwiek nie zostaną one zapisane do bazy danych (o ile nie zostaną ponownie połączone z EntityManager’em).
- Removed (usunięta) – obiekt jest usunięty z bazy danych. Podobnie jak metoda persist(), musi być wykonany w czasie trwania transakcji.
Czym jest JPQL?
JPQL (Java Persistence Query Language) jest niezależnym od platformy językiem, zdefiniowanym jako część JPA. Jest on używany w celu dokonywania operacji na relacyjnej bazie danych, z poziomu aplikacji o składni zbliżonej do standardowego SQL. Wykorzystując go, jesteśmy w stanie (niekiedy) dużo szybciej stworzyć interesujące nas zapytanie (bez tworzenia obiektów typu CriteriaBuilder i tworzenia zapytań przy jego pomocy). Zapytania JPQL przechowujemy w adnotacji @NamedQuery, która zawiera się w @NamedQueries, i jest przechowywana w danej encji, którą ma zwracać zapytanie. Zapytania te wywołujemy przy pomocy EntityManagera, wykorzystując metodę createNamedQuery().
To już chyba wszystko z tematu Java Persistence API. Jeżeli macie jakieś pytania bądź uwagi odnośnie tego zagadnienia piszcie śmiało na adres e-mail marek.makuch@it-leaders.pl, postaram się tam odpowiedzieć na Wasze pytania. Tymczasem – do następnego artykułu i powodzenia na rozmowach!
Następna część: Rozmowa kwalifikacyjna z Javy – Żaden problem! Cz. IX – Algorytmy i struktury danych
Autor: Marek Makuch
Oryginalny wpis pojawił się na naszym blogu w lipcu 2018r.
IT-Leaders.pl to pierwsza w Polsce platforma łącząca Specjalistów IT bezpośrednio z pracodawcami. Anonimowy, techniczny profil i konkretnie określone oczekiwania finansowe to tylko niektóre z cech wyróżniających platformę. Zarejestruj się i zobacz jak Cię widzi pracodawca.