
Witamy w kolejnym artykule z serii „Rozmowa kwalifikacyjna z Javy? Żaden problem!”. W poprzednim artykule omawialiśmy pytania z rozmów kwalifikacyjnych odnoszące się do jednej z najważniejszych klas w Javie – Stringa. W tym artykule przejdziemy do równie ważnego i często pojawiającego się w kodzie pojęcia – kolekcji. W artykule postaramy się zawrzeć najczęściej spotykane pytania z nimi związane – od najprostszych które przydadzą Ci się podczas rozmowy na wstępne stanowiska, aż po pytania które przydadzą się bardziej zaawansowanym developerom.
Kolekcje (Java Collections) są dość szerokim pojęciem i pojawiają się w praktycznie każdym bardziej zaawansowanym programie, dlatego dobre rozumienie podstaw ich działania jest przydatną umiejętnością na każdym stanowisku. Z tych powodów pytania odnośnie tego tematu pojawiają się bardzo często podczas rozmów, warto więc być dobrze przygotowanym i wiedzieć czym może spróbować zaskoczyć nas rekruter. Pytania które się tutaj pojawią są wykopane z głębi internetu oraz zasłyszane wśród fachowców z którymi mamy okazję współpracować. Jeżeli spotkaliście się z jakimś pytaniem które sprawiło Wam konkretną trudność, a nie pojawiło się w naszym tekście – dajcie znać, postaramy się znaleźć dla Was odpowiedź (bądź po prostu zamieścić ją dla innych użytkowników). Gotowi? Zaczynamy!
Czym jest Kolekcja (Collection)?
Kolekcją jest pojedynczy obiekt który pozwala na przechowywanie w nim wielu elementów. Kolekcje wiec są swojego rodzaju „kontenerem” do przechowywania innych obiektów w Javie. W odróżnieniu od tablicy kolekcje są bardziej zaawansowane oraz elastyczne – podczas gdy tablice oferują przechowywanie określonej ilości danych, kolekcje przechowują dane dynamiczne – pozwalają na dodawanie oraz usuwanie obiektów wedle Twojego życzenia.
Czym jest framework Kolekcji (Collections Framework)?
(słowa framework w dalszej części tekstu nie będziemy tłumaczyć – brzmi zdecydowanie lepiej niż „struktura kolekcji”;-) )
Framework kolekcji jest to zbiór struktur danych oraz algorytmów służących ułatwieniu organizacji danych dla programistów – tak aby sami nie musieli tworzyć odpowiadających im klas. W frameworku kolekcji zaimplementowane są najpopularniejsze struktury danych które są najczęściej wykorzystywane w programowaniu. Oferują one szereg metod służących przeprowadzaniu operacji na zbiorach (dodawanie, przeszukiwanie, usuwanie etc.) oraz doskonale prowadzoną dokumentację, dzięki czemu łatwo jest z nich korzystać. Najważniejsze Interfejsy definiowane przez framework to:
– Collection,
– List,
– Set,
– SortedSet,
– Map,
– SortedMap.
Jakie są zalety frameworka Kolekcji?
Przede wszystkim poprawiają szybkość działania oraz jakość pisanego przez nas oprogramowania – framework ten jest zbudowany aby dostarczyć nam wysoką wydajnośc i jakość. Kolejnym plusem jest zmniejszenie czasu potrzebnego na pisanie oprogramowania – nie musimy się skupiać na tworzeniu kontenerów samemu, możemy skupić się czysto na logice biznesowej. Ostatnim plusem jest to że framework jest wbudowany w JDK (Java Development Kit). Dzięki temu kod napisany z wykorzystaniem framework’u może być ponownie wykorzystany w innych aplikacjach oraz bibliotekach.
Jaka jest różnica pomiędzy Collection (Kolekcją) oraz Collections (Kolekcjami)?
Collection jest to interfejs Frameworku Kolekcji Javy, natomiast Collections jest to klasa użyteczna która posiada statyczne metody potrzebne do dokonywania operacji na obiektach typu Collection. Przykładowo – Collections zawiera metodę dzięki której odnajdziemy konkretny element, lub posortujemy nasz zbiór. Czym jest interfejs Collection doskonale widać na rysunku w kolejnym pytaniu.
Jakie są najważniejsze główne interfejsy zawierające się we frameworku kolekcji?
Najważniejsze z nich to:
– Collection,
– Set,
– Queue,
– Map.
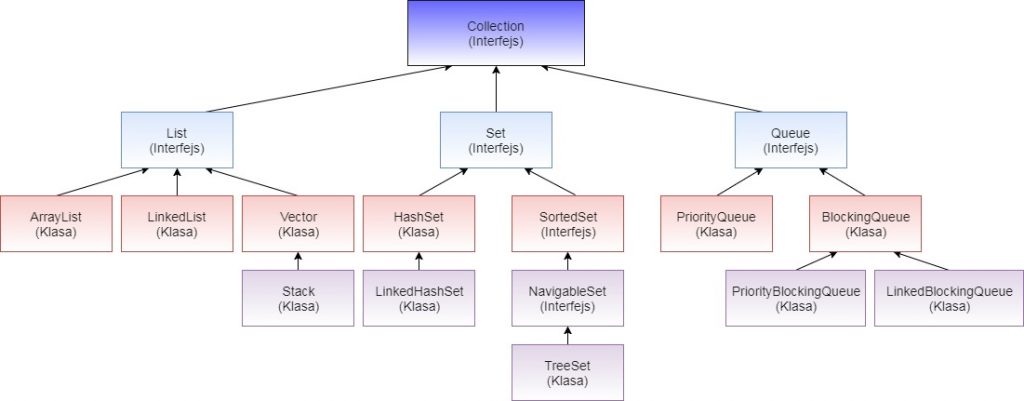


Po pierwsze zwróćmy uwagę na sposób formułowania pytania – nie mamy opowiedzieć o tym jakie rodzaje implementacji występują we frameworku kolekcji ale mamy opowiedzieć o poszczególnych implementacjach interfejsu Collection. Posiłkując się rysunkiem numer jeden widzimy że interfejsy które bezpośrednio implementują interfejs Collection to:
– List,
– Set,
– Queue.
I tak:
Lista (List) jest to uporządkowany zbiór obiektów w którym obiekty mogą występować więcej niż jeden raz. Przykładowo lista może przykładowo zawierać następujące elementy {1,2,3,4,5,1,2,3,8,11} i poprzez odwołanie się do indeksu nr. 3 zwróci nam element 4 (Uwaga matlabowcy – listy rozpoczynają się od zerowego indeksu!). Lista jest podobna do tablicy, przy czym lista potrafi dynamicznie zmieniać swoją długość. Pozwala ona również na dostęp do każdego elementu poprzez podanie jego indeksu. Najczęściej używane implementacje interfejsu List to ArrayList oraz LinkedList. Lista posiada również metody które pozwalają dodać, usunąć oraz zamienić element na konkretnym miejscu.
>> Sprawdź nasze aktualne oferty w obszarze: Java Developer
Zbiór (Set) – implementacje interfejsu Set nie mogą posiadać duplikujących się elementów. I tak przykładowo wykorzystując zbiór z poprzedniego tłumaczenia Listy oraz dodając go do obiektu za pomocą metody addAll() (Dodającej wszystkie elementy po kolei) nasz zbiór będzie zawierał wszystkie te elementy które się nie powtarzają, czyli {1,2,3,4,5,8,11}. Jeżeli chcemy wypisać wartości znajdujące się w implementacji Set musimy wykorzystać Iterator bądź specjalną składnię pętli for (Enhanced For Loop).
Kolejka (Queue) – kolejka pozwala na przechowywanie elementów w kolejności do przetworzenia. Jest uporządkowana ale elementy możemy dodawać tylko na „końcu” kolejki, natomiast usuwać tylko na „początku kolejki. Kolejki zazwyczaj (choć nie zawsze) ustawiają elementy według FIFO (first in, first out – tzn. ten który pierwszy wchodzi, pierwszy wychodzi. Wyjątkiem może być tutaj klasa PriorityQueue które porządkują elementy w zależności od dostarczonego obiektu klasy Comparator, bądź naturalnego kolejkowania.
Dlaczego interfejs Map znajduje się we frameworku kolekcji, ale nie implementuje interfejsu Collection?
To pytanie jest podchwytliwe – obecność we frameworku kolekcji nijak ma się do samego interfesju Collection. Mapy nie implementują tego interfejsu ponieważ różnią się od pozostałych elementów. Implementacje interfejsu Collection zakładają elementy o jednej wartości – natomiast mapy przyjmują elementy w parach klucz/wartość. Z tego powodu niektóre funkcje zawarte w interfejsie Collection nie byłyby kompatybilne ze strukturą map.
I krótka definicja mapy:
Mapy (Map) są to obiekty które mapują klucze do wartości. Mapa nie może posiadać dwóch takich samych kluczy – może natomiast posiadać dwie takie same wartości (pod warunkiem że mają różne klucze). Podstawowe implementacje interfejsu Map to HashMap, TreeMap oraz LinkedHashMap.
Czym jest Iterator?
Iterator jest to interfejs który udostępnia metody potrzebne do iterowania poprzez każdą z kolekcji. Dzięki Iteratorowi możemy przeprowadzać takie operacje jak odczyt oraz usunięcie.
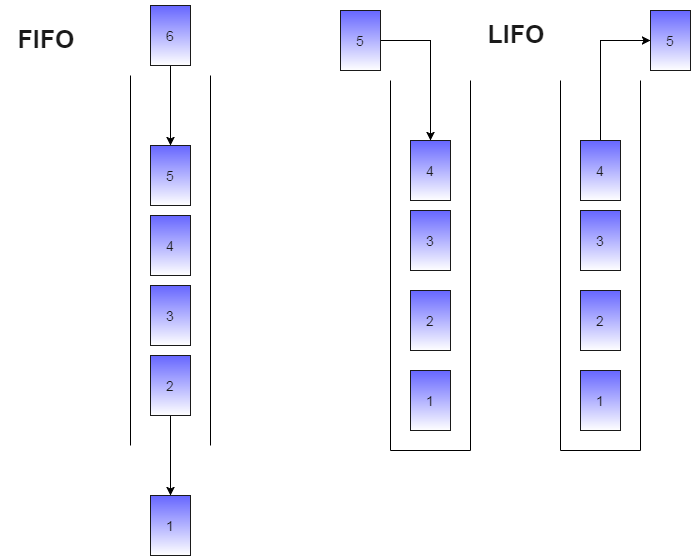
Jaka jest zasadnicza różnica pomiędzy Kolejką (Queue) a stertą (Stack)?
Raczej rzadko zadawane pytanie (z powodu rzadkiego użytkowania stert) – aczkolwiek warto znać na nie odpowiedź. Otóż jak mówiliśmy wcześniej kolejki zazwyczaj korzystają z FIFO (first in, first out) natomiast sterty działają w oparciu o LIFO (last in, first out) tzn. że ostatni element który dostał się do kolejki będzie pierwszym który się z niej wydostanie.
Pierwszą i najważniejszą różnicą pomiędzy tymi dwoma rodzajami listy jest to że (jak sama nazwa wskazuje) ArrayList jest implementowany przy pomocy dynamicznie zmieniającej swoje rozmiary tablicy, natomiast LinkedList jest implementowany przy pomocy podwójnie łączonej listy (doubly LinkedList). Co to tak właściwie oznacza? Aby ułatwić podrzucamy rysunek:
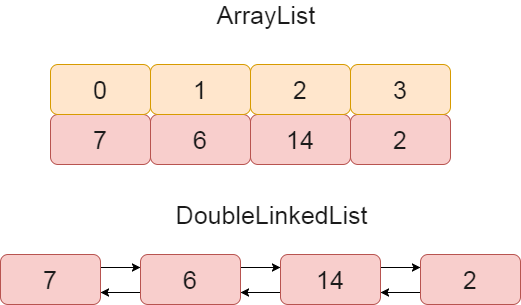
Jak widać ArrayList przechowuje informacje o tym pod jakim indeksem znajduje się dana wartość, natomiast Double LinkedList przechowuje informacje o następnym i poprzedzającym elemencie. Wynikają z tego następujące różnice:
– odczyt elementu – ponieważ ArrayList działa na indeksach jest znacznie szybszy niż LinkedList, potrzebna jest mniejsza ilość operacji aby odczytać wartość pod danym indeksem. Aby odszukać daną wartość w LinkedList należy przeiterować przez całą listę, co z pewnośćią jest znacznie bardziej czasochłonne.
– usuwanie elementu – w tej sytuacji korzystniej zachowuje się LinkedList. Spowodowane jest to tym że po usunięciu danego elementu zmianie podlegają tylko odnośniki do kolejnego (bądź poprzedniego) elementu w dwóch elementach obok usuwanego. W przypadku ArrayList musimy zmienić położenie wszystkich elementów znajdujących się za usuwanym elementem – powoduje to znacznie większy koszt w porównaniu do LinkedList.
– dodawanie elementów – dodawanie elementów w LinkedList jest łatwe i szybkie w porównaniu do ArrayList gdyż nie istnieje ryzyko powiększenia tablicy i kopiowania zawartości do nowej tablicy. Co to oznacza? Jeżeli dodana wartość sprawia że tablica na której opiera się ArrayList staje się pełna, program musi stworzyć nową, większą tablicę i przekopiować tam wszystkie dane z poprzedniej tablicy. Dodatkowo ArrayList musi również zmienić indeksy poszczególnych wartości jeżeli element nie jest dodany na końcu listy.
– pamięć – LinkedList potrzebuje więcej pamięci gdyż w odróżnieniu od ArrayList (w którym każdy indeks przechowuje jakieś dane) musimy przechowywać informacje o adresach i danych poprzedniego oraz następnego elementu.
Jaka jest różnica pomiędzy HashMap i Hashtable?
Istnieje kilka różnic:
– Hashtable jest zsynchronizowane (synchronized) natomiast HashMap nie jest. Oznacza to że HashMap funkcjonuje lepiej w aplikacjach które nie są wielowątkowe gdyż niezsynchronizowane obiekty mają wyższą wydajność niż obiekty zsynchronizowane.
– Hashtable nie zezwala na używanie wartości null jako klucza i wartości, natomiast HashMap zezwala na używanie jednego klucza o wartości null, oraz nielimitowanej ilości wartości null.
– HashMap do Iteracji poprzez wartości obiektów wykorzystuje Iterator, natomiast Hashtable enumerator.
– HashMap jest dużo szybszy niż Hashtable.
Warto zwrócić uwagę że Hashtable może być również zastąpiony przy pomocy ConcurrentHashMap, który również jest przystosowana do pracy z aplikacjami wielowątkowymi, a oprócz tego oferuje również większą szybkość działania.
Jaka jest różnica pomiędzy interfejsami Iterator oraz ListIterator?
ListIterator pozwala na przeszukiwanie listy w obie strony (podczas gdy Iterator przeszukuje listę tylko w jedną stronę). ListIterator może być używany tylko do List. Ponadto ListIterator pozwala również na dodawanie elementów, oraz zmianę ich wartości – podczas gdy zwykły Iterator umożliwia jedynie usuwanie elementów.
Jaka jest różnica pomiędzy HashSet a TreeSet?
Występuje kilka różnic pomiędzy tymi strukturami:
– HashSet zachowuje elementy w losowej kolejności (ta klasa nie jest w stanie zagwarantować nam stałej kolejności) podczas gdy TreeSet gwarantuje że przechowywane wartości będą posortowane w kolejności naturalnej bądź ułożone według naszych specyfikacji zawartych w konstruktorze.
– HashSet może przechowywać obiekt o wartości null, podczas gdy TreeSet nie może.
– Hashset oferuje stałą szybkość działania (O(1)) podczas gdy szybkość działania TreeSet jest wyliczana logarytmicznie (log(n)).
Sprawdź aktualne oferty pracy JAVA Developer
Na jakiej zasadzie działa HashMap?
Trudne i ważne pytanie – przed każdą rozmową warto sobie je powtórzyć 😉
HashMap działa w oparciu o zasadę hashowania (hashing), mamy metodę put(key, value) oraz metodę get(key), które służą do zapisywania oraz odczytywania obiektów z HashMap. Kiedy stosujemy metodę put() implementacja HashMap wywołuję metodę hashCode() na kluczu obiektu i przetwarza zwrócony hashcode swoją własną metodą hashującą, aby znaleźć miejsce w bucket-cie na przechowywanie obiektu typu Entry. Warto wspomnieć że HashMap przechowuje zarówno klucz jak i wartość jako Map.Entry w bucket-cie.
Kiedy chcemy wydobyć swój obiekt używamy metody get() i ponownie podajemy obiekt który jest naszym kluczem. Ponownie obiekt generuje ten sam hashkod (obowiązkowe jest to ązeby klucz generował ten sam hashkod – z tego powodu klucze HashMap są niezmienne jak np. String) i tym samym trafiamy do tego samego bucket-u co przy zapisywaniu.
Wnętrze HashMap ma ograniczony rozmiar (jest ograniczona liczba bucket-ów) a więc nieuniknione jest aby dwa zapisane obiekty znajdowały się w tym samym bucket-cie. Taka sytuacja nazywa się kolizją – w takim przypadku zamiast pojedynczego obiektu w bucket-ach przechowywane są listy typu LinkedList a kolejny obiekt przechowywany jest jako następny wpis na tej liście.
W przypadku chęci odczytania obiektu z takiej listy potrzebne jest dodatkowe sprawdzenie czy dany obiekt jest tym który chcemy odzyskać. Ponieważ każdy wpis zawiera obiekt typu Entry, HashMap sprawdza czy podany klucz odpowiada kluczowi obiektu typu Entry (przy pomocy metody equals(). Jeżeli wynikiem metody będzie true, HashMap zwraca dany obiekt.
Trochę skomplikowane prawda? Warto jednak znać odpowiedź na to pytanie – bardzo często pojawia się ono na rozmowach na stanowiska mid-senior.

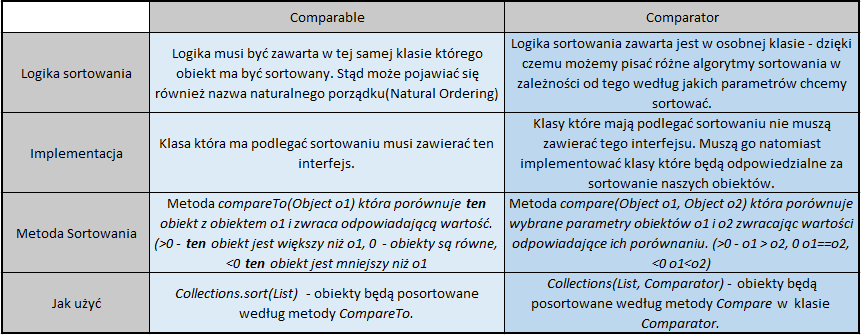
Comparable – wszystkie klasy które mają być posortowane przy użyciu tego interfejsu muszą implementować ten interfejs. Wraz z tym interfejsem otrzymywana jest metoda compareTo(Object) która musi zostać zaimplementowana.
Comparator – klasy które mają być posortowane nie muszą implementować tego interfejsu. Inna klasa może implementować ten interfejs aby posortować dane obiekty. Wykorzystując Comparator możemy tworzyć różne algorytmy sortowania opierające się na różnych atrybutach.
Różnice przedstawione są w tabelce:
Sprawdź aktualne oferty pracy JAVA Developer
Następna część: Rozmowa kwalifikacyjna z Javy? Żaden problem! Cz. III (Core)
Autor: Marek Makuch
Oryginalny wpis pojawił się na naszym blogu w lipcu 2018r.
IT-Leaders.pl to pierwsza w Polsce platforma łącząca Specjalistów IT bezpośrednio z pracodawcami. Anonimowy, techniczny profil i konkretnie określone oczekiwania finansowe to tylko niektóre z cech wyróżniających platformę.