
Witamy w kolejnym artykule z serii „Rozmowa kwalifikacyjna z Javy – żaden problem!”. W dzisiejszym artykule w kontraście do poprzedniego podejmiemy trochę trudniejsze zagadnienie – tematykę wielowątkowości w Javie. Pytania z tej dziedziny pojawiają się najczęściej podczas rozmów na stanowiska, które wymagają więcej doświadczenia, dlatego cały artykuł jest w dużej mierze skierowany do specjalistów aplikujących na pozycje seniorskie lub pośrednie pomiędzy juniorem a seniorem. Nie oznacza to jednak, że osoby z mniejszym doświadczeniem powinny sobie ten artykuł odpuścić – podczas rozmowy Wam również mogą się przytrafić pytania z tej tematyki, dlatego warto mieć na ten temat chociażby podstawowe pojęcie. Skoro przebrnęliśmy przez wstęp, zabierajmy się do roboty!
>> Sprawdź nasze aktualne oferty w obszarze: Java Developer
Co oznacza stwierdzenie, że Java jest wielowątkowym językiem programowania?
Oznacza to, że w Javie możemy tworzyć aplikacje, w której dwie (lub więcej) części programu mogą działać równocześnie wykonując dwie równe czynności, wykorzystując przy tym procesor komputera, który posiada kilka rdzeni.
Jaka jest różnica pomiędzy procesem (Process) a wątkiem (Thread)?
Wykonywany program jest określany, jako proces, wątek natomiast zawiera się bezpośrednio w procesie. Jeden proces może zawierać kilka wątków, wątek jest, więc najmniejszą częścią procesu, którą może działać współbieżnie do innych wątków.
Jakie są dwa podstawowe sposoby implementacji wątków w Javie?
Bardzo ważne pytanie, pojawia się niespotykanie często podczas tematyki wielowątkowości na rozmowach kwalifikacyjnych (często, jako pierwsze pytanie). Pierwszym sposobem jest utworzenie klasy, która rozszerza klasę Thread i nadpisuje metodę .run(), podając do niej kod, który ma być wykonywany w osobnym wątku. Następnie programista musi utworzyć instancję tej klasy i wykonać na niej odziedziczoną metodę .start(), aby rozpocząć wykonywanie kodu zawartego w metodzie run().
Drugim sposobem jest implementowanie przez klasę interfejsu Runnable, od którego klasa dostaje również metodę .run(), której działanie musimy zaimplementować. Następnie tworzymy obiekt klasy Thread (np. t1) i do konstruktora podajemy klasę implementującą interfejs Runnable i na obiekcie (t1) wykonujemy metodę .start(). Warto nadmienić, że metoda run() jest tą samą metodą – po prostu klasa Thread wewnętrznie implementuje już interfejs Runnable. Jak że obrazek przedstawia więcej niż tysiąc słów, poniżej znajduje się mała grafika.
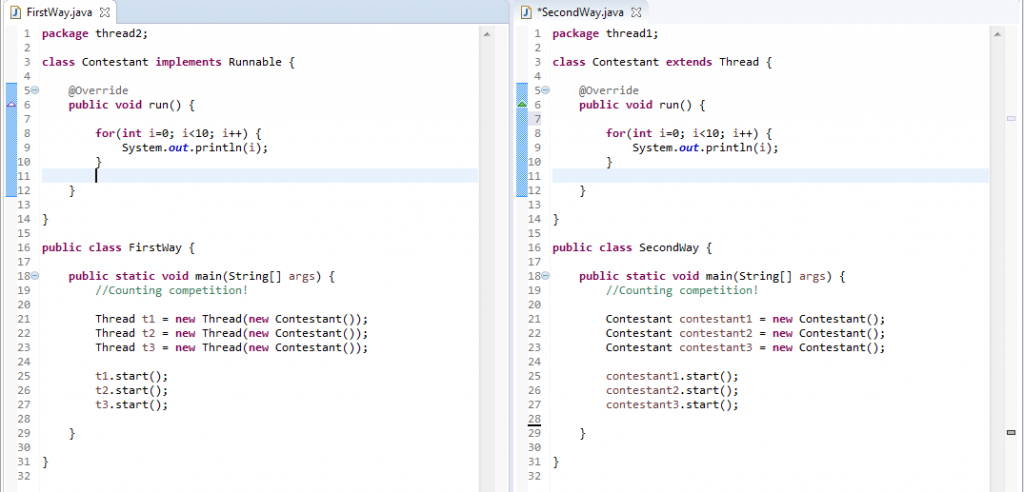
To pytanie bardzo często pojawia się po pytaniu nr 3. Pierwsza i najważniejsza różnica wynika z konstrukcji języka Java, otóż klasa może dziedziczyć tylko po jednej klasie, może natomiast implementować nieograniczoną ilość Interfejsów. Rozszerzanie jest mniej elastyczne, a więc implementacja interfejsu powinna być bardziej preferowana podczas tworzenia aplikacji wielowątkowych. Dzięki temu może dziedziczyć po innej klasie, która rzeczywiście jest logiczną nadklasą naszej klasy.
Czy jest możliwe, aby uruchomić wątek dwukrotnie?
Nie jest to możliwe. W sytuacji gdy wywołamy metodę .start() na tym samym wątku, program zwróci nam wyjątek (IllegalThreadStateException). Innymi słowy, wątek może być wystartowany tylko jeden raz w cyklu swojego życia.
Czy możemy użyć metody .run() zamiast metody .start()?
Można, jak najbardziej. Problemem jest jednak to że wykonanie samej metody .run() nie rozpoczyna innego wątku (wykonywana jest w tym samym wątku w którym została wywołana). Metoda .start() natomiast wywołuje metodę .run() w nowo utworzonym wątku.
Jak jest różnica pomiędzy Runnable oraz Callable?
Interfejs Runnable został wprowadzony już w Javie 1, natomiast Callable dopiero w Javie 1.5. Najważniejszą różnicą pomiędzy tymi interfejsami jest to, że Callabe jest w stanie zwrócić nam jakąś wartość, oraz wyrzucić wyjątek. Zwracana wartość jest klasy Future, która jest swojego rodzaju obietnicą tego, że z operacji asynchronicznej zostanie zwrócony jakiś obiekt. Klasa ta umożliwia nam sprawdzenie czy dana operacja dobiegła końca (tak abyśmy nie pobrali wartości, która jeszcze nie istnieje) a następnie pobranie jej wartości.
Co oznacza słówko synchronized przy deklarowaniu metody? Jakie jest jego zastosowanie?
Słówko synchronized jest używane, aby zapobiegać sytuacji, w której dwa różne wątki korzystające z tego samego zasobu nadpisują wykonane przez siebie różnice w danym zasobie. Dzieje się tak w momencie, kiedy wykonanie danej operacji nie odbywa się w jednym kroku (np. operacja inkrementacji i++ nie dzieje się w jednym kroku, przez co dwa różne wątki operujące na zmienne i mogą zmienić nadpisywać swoje dokonania). Brzmi to dość skomplikowanie, dlatego postaramy się to wytłumaczyć przy pomocy rysunku:
Na pierwszy rzut oka z powyższą klasą jest wszystko dobrze i powinna poprzez inkrementację doprowadzić zmienną count do wartości 10 000. Jest stworzona poprzez wyrażenie lambda implementacja interfejsu Runnable, są stworzone dwa różne wątki oraz na poszczególnych wątkach są wykonane metody .join() (metoda ta informuje program, że ma poczekać do zakończenia operacji w danym wątku przed przejściem do dalszej części poleceń). Spróbuj jednak napisać uruchomić powyższy kod. Co zauważyłeś? Otóż metoda działa niedeterministycznie – wynik operacji nie zawsze jest równy 10 000 (wykonaj program kilka razy). Dzieje się tak, ponieważ operacja inkrementacji nie jest wykonywana w jednym kroku, dlatego obydwa wątki wykonujące pracę na jednej zmiennej nadpisują niekiedy dokonania drugiego wątku. Spróbujmy jednak pewnej modyfikacji:
Jaki wynik otrzymamy po tej modyfikacji? Zmienna counter pod koniec działania programu zawsze będzie miała wartość 10 000. Mechanizm działania słówka synchronized opiera się na pobieraniu oraz zwalnianiu zamku (monitor lock). Każdy obiekt w Javie posiada swój monitor lock (w naszym przypadku pobierany jest klucz obiektu SynchronizedMethod). Synchronizacja „pobiera” zamek, gdy wykonywana jest metoda i zwalnia go po wykonaniu czynności. Dopiero wtedy inny wątek może wykonać metodę danego obiektu.
Co to znaczy, że obiekt lub kod jest bezpieczny dla pracy z wątkami (Thread Safety)?
Oznacza to, że obiekt (lub kod) gwarantuje, iż będzie się zachowywał wedle przewidywań nawet w sytuacji, gdy kilka różnych wątków będzie z nim współpracować. Klasy można, więc podzielić wedle kryterium bezpieczeństwa w pracy z wieloma wątkami. I tak na przykład z poprzednich artykułów wiemy, że StringBuilder oraz StringBuffer działają z różną szybkością (StringBuilder jest szybszy), ale zaletą oferowaną przez StringBuffer jest to, iż jest on zsynchronizowany, przez co możemy z niego spokojnie i bezpiecznie korzystać w aplikacjach wykorzystujących kilka wątków.
Za co odpowiada słówko kluczowe volatile przed zmienną w Javie?
Jeżeli na zmiennej zadeklarowanej w klasie, mają być wykonywane różne czynności za pomocą kilku wątków (np. zapis do zmiennej, oraz odczyt jej wartości) to deklarujemy wtedy zmienną słówkiem kluczowym volatile. Słówko to gwarantuje, że czynności zapisu będą wykonywane przed odczytem. Dzięki temu jesteśmy pewni, że utrzymana zostanie spójność działania danego procesu.
Powyższa klasa testVolatile tworzy nowy wątek klasy Dog o nazwie hachiko i wykonuje pętle wypisującą „Bork!” na ekran. W klasie Dog, aby zaznać chwilę spokoju od jakże uroczego szczekającego psa, znajduje się również metoda shhhhh() która umożliwia nam zatrzymanie działania pętli szczekania. Zmienna canDogBork została zadeklarowana, jako volatile, gdyż w przypadku, gdy główny wątek wywołałby metodę shhhhh() pętla mogłaby się nie zatrzymać. Spowodowane jest to tym, iż wątek Dog może mieć zapisaną w swojej „pamięci” kopie zmiennej canDogBork o wartości true – nawet w sytuacji, w której zmienna zostałaby zmieniona przez inny wątek pętla mogłaby dalej działać. Dzięki zadeklarowaniu zmiennej, jako volatile zapis odbywa się przed odczytem i pętla while przed odczytem sprawdza czy wartość zmiennej canDogBork uległa zmianie.
Czym jest pula wątków (Thread Pool)?
Pula wątków jest to grupa predefiniowanych wątków, którym możemy powierzyć zadania do wykonania. Jest to wskazane przy wykonywaniu dużej ilości małych zadań przez różne wątki. Tworzenie nowych wątków jest kosztowną operacją – a więc w przypadku wykonywania dużej ilości małych czynności koszty rosną w szybkim tempie. Poprzez pulę, (czyli kilku wątków stworzonych przy inicjalizacji klasy ExecutorService) wykorzystujemy do tych operacji cały czas te same wątki, przez co unikamy ich kosztownego tworzenia. Przykład kodu poniżej:
Jak widać na rysunku nr. 5 Tworzymy najpierw zadanie do wykonania (implementujące Runnable). Dodatkowo, aby ułatwić dodajemy konstruktor, w którym opisujemy nadajemy nazwę zadania do wykonania. Następnie w klasie Application tworzymy listę zadań do wykonania oraz instancje klasy ExecutorService. Metaforycznie ta klasa jest naszą „kadrą” – w tym przypadku mamy dwóch pracowników (stworzonych poprzez Executors.newFixedThreadPool(2)) którym najpierw w pętli for przydzielamy zadania, a oni potem zajmują się wykonaniem przydzielonych zadań (przyjmujemy, że jeden pracownik może wykonać jedno zadanie na raz). Metoda executor.shutdown() pozawala na wykonanie wszystkich zadań przed zamknięciem obiektu ExecutorService. Wynik tych operacji widać w konsoli – kolejne zadania podejmowane są dopiero po ukończeniu poprzedniego przydzielonego zadania.
To była ciężka przejażdżka! Jeżeli macie jakieś inne pytania, na które chcielibyście dostać odpowiedzi, piszcie w komentarzach, postaramy się je uwzględnić w kolejnych artykułach z tej serii. Dodatkowo, jeżeli macie jakieś uwagi również piszcie – dzięki temu będziemy mogli tworzyć materiały lepszej jakości w przyszłości. Do zobaczenia w kolejnym artykule!
Następna część: Rozmowa kwalifikacyjna z Javy? Żaden problem! Cz. V (Wzorce projektowe)
Autor: Marek Makuch
Oryginalny wpis pojawił się na naszym blogu w lipcu 2018r.
IT-Leaders.pl to pierwsza w Polsce platforma łącząca Specjalistów IT bezpośrednio z pracodawcami. Anonimowy, techniczny profil i konkretnie określone oczekiwania finansowe to tylko niektóre z cech wyróżniających platformę. Zarejestruj się i zobacz jak Cię widzi pracodawca.
B
Marek Makuch
em320
Buczek